Digest -- Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer (Raffel et al., 2020).
Summary
This paper is more engineering-oriented than method-oriented in my opinion. It doesn’t propose new model architectures or training techniques. Yet the contribution of this paper is tremendous. With the goal of investigating the exact contribution of various architectures, training objectives, techniques, and training datasets on transfer learning in NLP, the authors perform a series of systematic experiments and show us the optimal and promising strategies to consider empirically. Afterwards, they combine all of their findings and propose a pre-trained model T5 and the dataset C4. Another highlight is that they use a unified text-to-text framework in the study, namely, transform every NLP tasks into a text-to-text.
The logic to use a unified framework, to my understanding, is that if it can achieve good results across a wide range of tasks, then it may be implied that the model has indeed learned something universal in natural languages.
T5: Text-to-Text Transfer Transformer
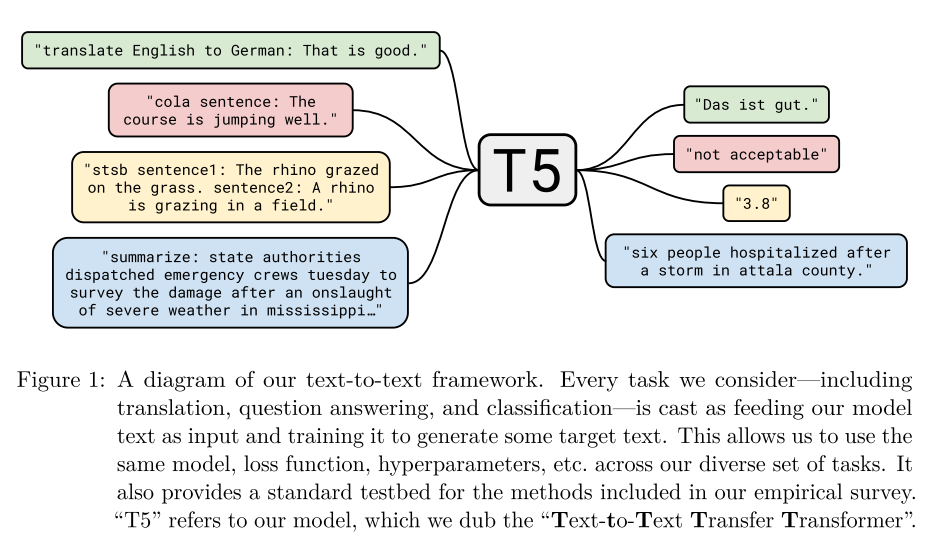
The architecture in the framework is encoder-decoder, so every task should be transformed in an input-output format, where both are text. To help the model identify the specific task to perform, the task name is appended at the beginning of the input. The excellence of T5 comes from the combination of optimal strategies with respect to multiple aspects, including encoder-decoder architecture, corrupting span denoising objective, C4 pre-training data set, Multi-task pre-training + fine-tuning on downstream tasks, and scaling in terms of model sizes and training time.
Experiment Results
Architectures: three types are compared: encoder-decoder, decoder-only language models, decoder-only prefix language models. Controlling the number of parameters, encoder-decoder is the best across all downstream tasks.
Unsupervised Objectives: the flow chart below shows their exploration and the table illustrates these objectives by an example (the captions are include details about the experiment). They choose the corrupted span denoising objective in that the computation cost can be reduced while maintaining comparable performances as the baseline.
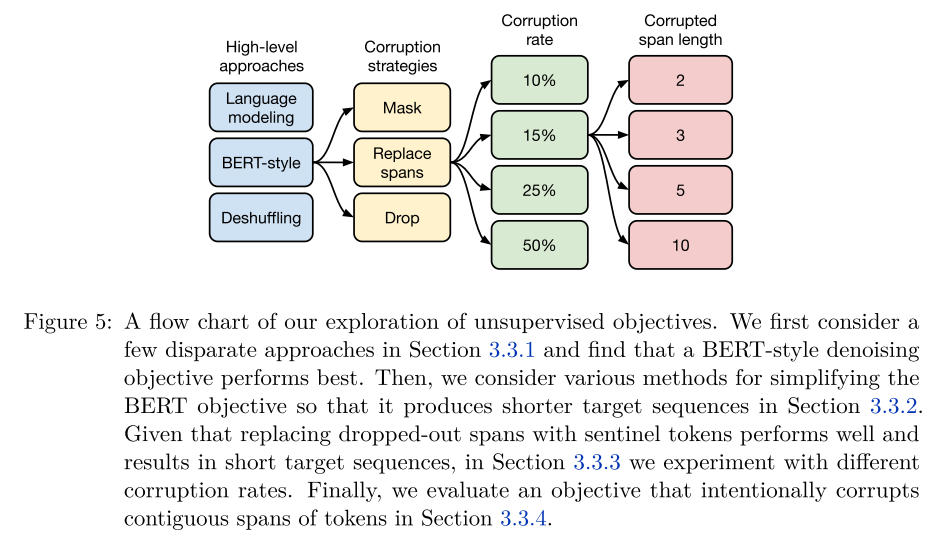

A detailed illustration of the objective is as below.

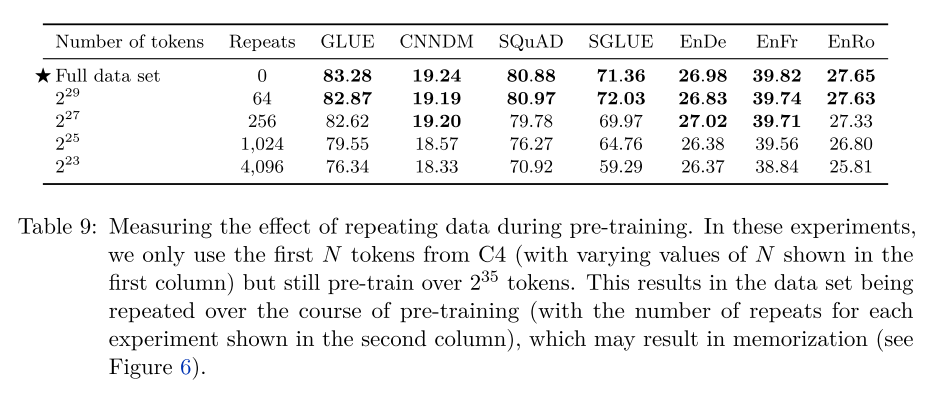
Pre-training Data Set: they find that pre-training on in-domain unlabeled data can improve performance on downstream tasks, for example, SQuAD, which is based on Wikipedia. Also, with regard to the data set size, they find that some amount of repetition of the pre-training data might not be harmful.
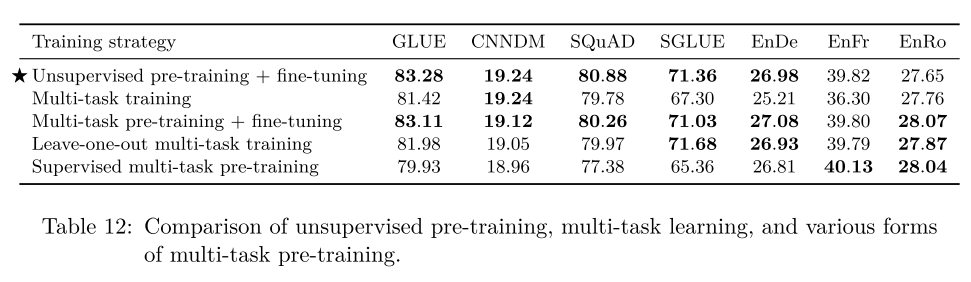
Training Strategy: they experiment three fine-tuning strategies and find that fine-tuning all parameters is the best. They also consider multi-task learning, where they mix the unsupervised task with the other tasks and explore three strategies of setting the proportion of data coming from each task. It turns out first pre-training on the unsupervised task and then fine-tuning on the downstream tasks outperforms the multi-task training strategies. They then combine multi-task learning with fine-tuning and compare different strategies as below. Since multi-task pre-training + fine-tuning has similar performance as unsupervise pre-training + fine-tuning, and that it enables us to monitor the “downstream” performance for the entire duration of traininng, instead of just fine-tuning, the authors use this strategy in their final T5 model.
Scaling: they focus on addressing this question: “You were just given 4× more compute. How should you use it?” They find that in general, increasing the model size resulted in an additional bump in performance compared to solely increasing the training time or batch size. And ensembling provides an orthogonal and effective means of improving performance through scale.
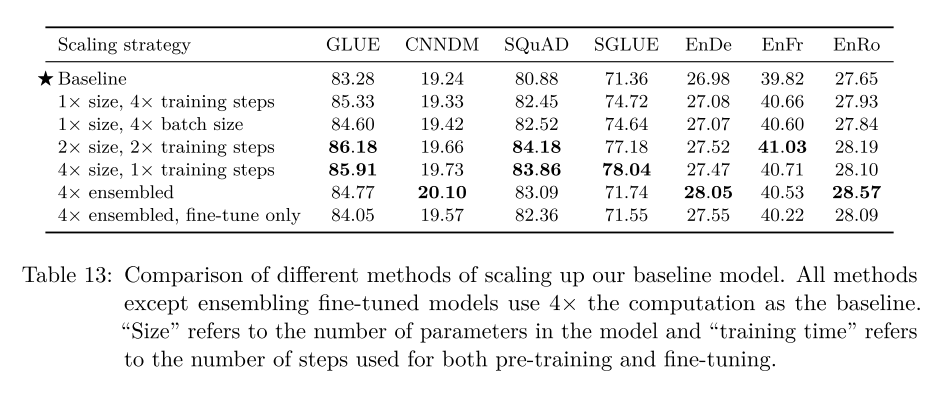
In the end, they put together all of their findings, combine the optimal settings, and come up with T5, a pre-trained model with state-of-art performances on many leaderboards.
Related topics to read
- Multi-task Learning: An Overview of Multi-Task Learning in Deep Neural Networks
References
- Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., & Liu, P. J. (2020). Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 21(140), 1–67.