Digest -- Abstractive text summarization using sequence-to-sequence RNNs and beyond
Abstractive text summarization using sequence-to-sequence RNNs and beyond (Nallapati et al., 2016).
Summary
This paper uses the sequence-to-sequence RNN framework with attention as the baseline and proposes a model that is specially designed to tackle the unique patterns of abstractive text summarization. Their model is able to model key-words, to capture the hierarchy of sentence-to-word structure, and to deal with OOV words in summarization. Another contribution of this paper is that they transform the CNN/Daily Mail datasets from a question-answering dataset to a dataset for text summarization, which greatly facilitate later research work.
- How did they use model architectures to tackle summarization specific issues?
- What is the training objective?
- What problems remain unsolved?
Model Architecture
The sequence-to-sequence encoder-decoder framework is borrowed from NMT.
In summarization, there are several challenges:
- identify the key concepts and key entities
- model rare or unseen words, ex. the name of a particular product
- capture the document hierarchy, namely, a document is made up of sentences, which are made up of words.
To tackle the above mentioned challenges, the authors proposed several strategies corresponding.
- Incorporate the linguistic features in the embedding vectors, such as NER, TF, and IDF.
- Use Generator-Pointer network, where generator is used for generating words in the vocabulary while pointer intends to copy words directly from the source text. This design is further improved later by (See et al., 2017).
- Use hierarchical attention to model the hierarchy of documents.
The main idea of the three strategies is fully illustrated in the diagrams as below.
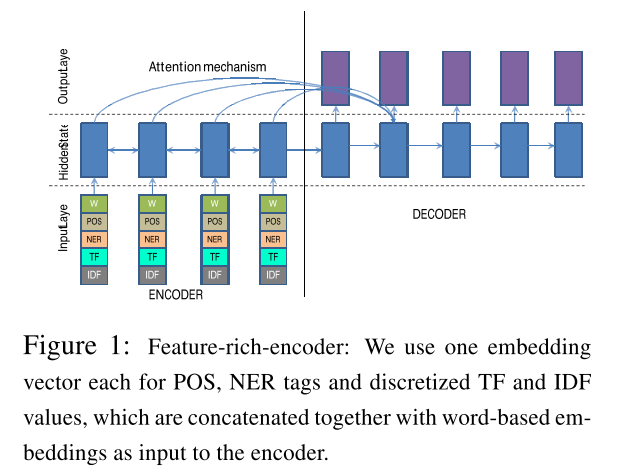
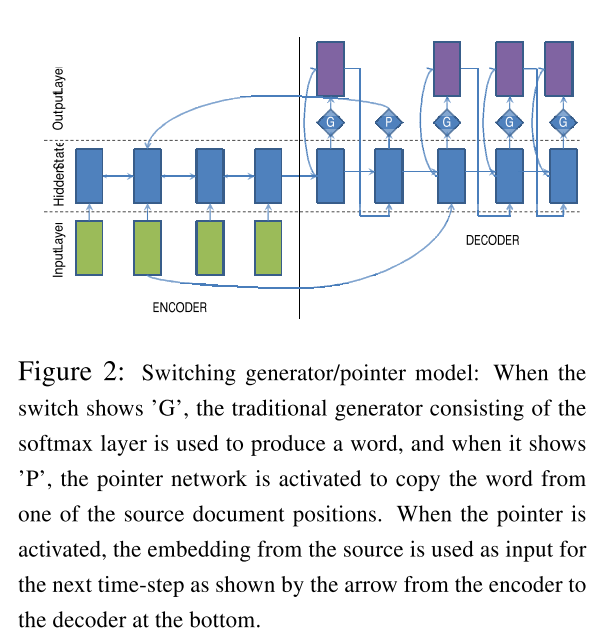
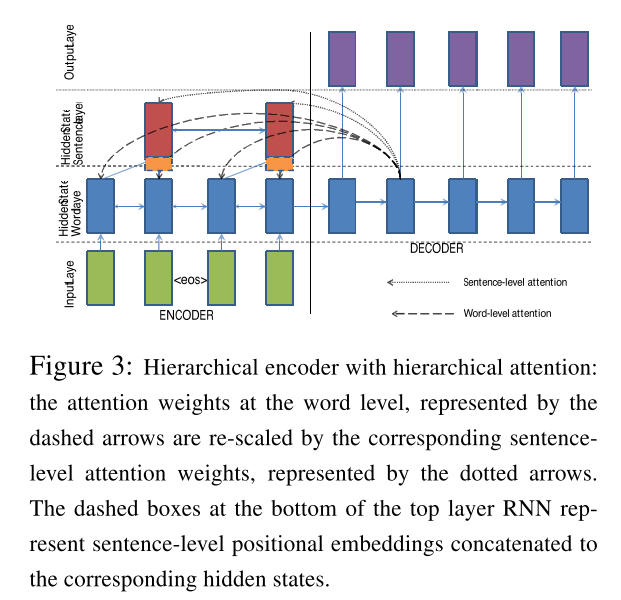
Training Objective
The training objective is the conditonal log-likelihood plus additional regularization penalties.
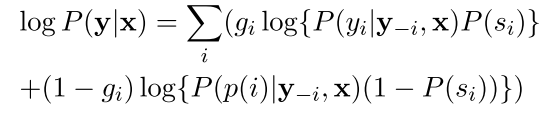
where y and x are the summary and document words respectively, and $g_i$ is an indicator function that is set to 0 whenever the word at position $i$ in the summary is OOV w.r.t. the decoder vocabulary.
Unsolved problems
One interesting thing is that although the model in (Chopra et al., 2016) is less sophisticated, where the encoder uses convolutional attention and the decoder is the plain RNN, its performance can beat the much more complex system proposed in this paper w.r.t. some criteria. More effort should be put on to investigate the reasons.
References
- Nallapati, R., Zhou, B., dos Santos, C., Gu̇lçehre Çağlar, & Xiang, B. (2016). Abstractive Text Summarization using Sequence-to-sequence RNNs and Beyond. Proceedings of The 20th SIGNLL Conference on Computational Natural Language Learning, 280–290.
- See, A., Liu, P. J., & Manning, C. D. (2017). Get To The Point: Summarization with Pointer-Generator Networks. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 1073–1083.
- Chopra, S., Auli, M., & Rush, A. M. (2016). Abstractive sentence summarization with attentive recurrent neural networks. Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 93–98.