Digest -- A Neural Attention Model for Abstractive Sentence Summarization Alexander
A Neural Attention Model for Abstractive Sentence Summarization Alexander (Rush et al., 2015).
Summary
This is a highly cited paper in abstractive summarization. It might be the first paper to use neural attention in the encoder of the ABS system. The architecture of the model may not look fancy nowadays, but the key concepts and definitions in this paper are well worth noting. The definitions give a high level about the problem set up, and I really recommend a closer look at the Background section and the Encoders subsection.
Problem Setup
One highlight is that this paper defines the problem using a scoring function $s$, which is a more general concept than conditional probabilities. Currently, most papers focus on optimizing the conditional probability, while at the same time, it might be worthwhile to think about other sensible score functions.
Let x be the original text and y be the summary. An abstractive system optimize (1) while an extractive system works on (2), and a sentence compression system works on (3).
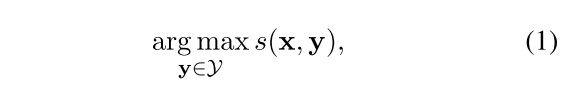
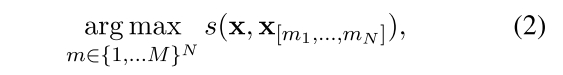
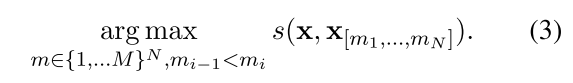
A few personal thoughts:
- Extractive summarization is in general easier than abstractive summarization. It is probably due to the constraint imposed in (2). Is it possible to simplify the abstraticve system by adding some sensible constraints?
Another highlight is that they consider a special case of scoring function, which is still more general than conditional probabilities, namely, the factored scoring functions.
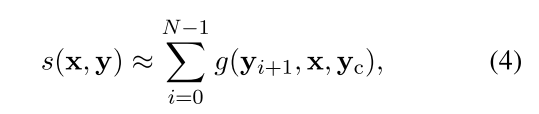
| In terms of conditional probability, $s(x, y) = \log p(y | x;\theta)$ and |
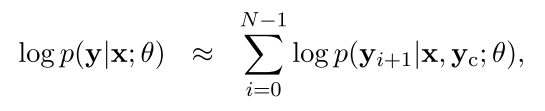
Model
This paper compares three encoders: Bag-of_Words Encoder, Convolutional Encoder, and Attention-Based Encoder.
- Bag-of_Words Encoder: can capture the relative importance of words to distinguish con- tent words from stop words or embellishments.
- Convolutional Encoder: improves on the bag-of-words model by allowing local interactions.
- Attention-Based Encoder: can informally think of it as replacing the uniform distribution in bag-of-words with a learned soft alignment between the input and the summary.
References
- Rush, A. M., Chopra, S., & Weston, J. (2015). A Neural Attention Model for Abstractive Sentence Summarization. Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, 379–389.